2.Word2vec
Word2vec
NLP 모델 중 하나
개념
- ‘주위 단어가 비슷하면 해당 단어의 의미는 유사하다’라는 아이디어.
- 단어, 구, 문장, 단락, 문서의 의미를 알아내는 작업을 함.
- 단어를 계산에 적용할 수 있는 숫자로 변환해서 다음에 올 단어를 예측하는 모델.
- 다음 단어를 예측하기 위해 Word Embedding을 구현해야 하는데, CBOW 또는 Skip-Gram 알고리즘을 사용.
- 기존의 알고리즘에 비해 자연어 처리에서 엄청난 향상을 가져왔다.
- 변환된 벡터가 단순한 수학적 존재 이상의 복잡한 개념 표현을 넘어 추론까지도 쉽게 구현할 수 있다는 점에서 대단한 의미를 가짐.
- 단어를 트레이닝 시킬 때 주위 단어를 label로 매치하여 최적화
- 단어를 의미를 내포한 dense vector로 매칭하는 것
종류
CBOW(Continuous Bag-of-Words)
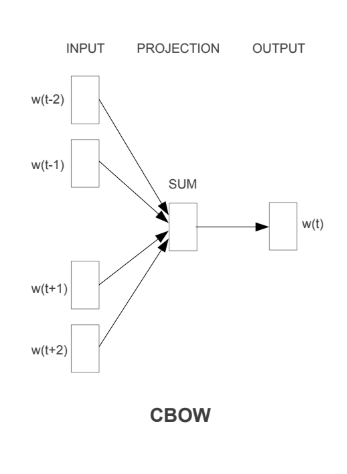
- 컨텍스트로부터 찾고자 하는 목표 단어를 예측하는 모델을 말함.
- 주어진 단어에 대해 앞 뒤로 N/2개 씩 총 N개의 단어를 입력으로 사용하여, 주어진 단어를 맞추기 위한 네트워크를 만듦.
- 크기가 작은 데이터셋에 적합.
- 예시: 문장안에 들어갈 단어를 예측
-
- __ 가 맛있다.
-
- __ 를 타는 것이 재미있다.
-
- 평소보다 두 __ 로 많이 먹어서 __ 가 아프다.
-
Skip-Gram
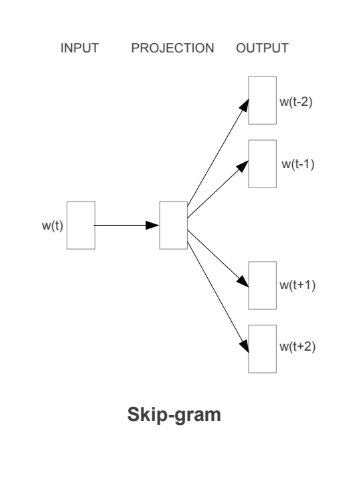
- 처리하려고 하는 현재의 단어 하나를 사용해서 주변 단어들의 발생을 유추하는 모델.
- 예측하는 단어들은 현재 단어 주변에서 샘플링.
- ‘가까이 있는 단어일수록 현재 단어와 관련이 더 많다’는 원리를 적용하기 위해 멀리 떨어진 단어를 낮은 확률로 선택하는 방법을 사용.
- 나머지는 CBOW 모델과 방향만 반대이고 거의 비슷함.
- Skip-Gram 모델은 크기가 큰 데이터셋에 적합하여, 최근일수록 더욱 많은 데이터를 갖고 있기 때문에 주로 Skip-Gram 모델 사용.
- 예시: 특정 단어 주변에 올 수 있는 단어 예측
-
- -배- 가 맛있다.
-
- -배-를 타는 것이 재미있다.
-
- 평소보다 두 -배-로 많이 먹어서 -배-가 아프다.
-
Skip-Gram 모델
- 구문론적 컨텍스트를 정의.
- Skip-Gram 모델은 현재 단어로부터 컨텍스트를 예측한다는 점을 상기.
- 목적 함수는 전체 데이터셋에 대해 정의될 수 있다. 그러나, 성능상의 이류로 보통 Stochastic Gradient Descent(SGD) 알고리즘을 사용해서 하나 또는 minibatch라고 부르는 일정 개수의 데이터로 묶어서 최적화.
- 일반적으로 데이터 개수는 (16<= 크기 <= 512)임.
용어정리
Word Embedding
- 고차원의 데이터를 그보다 낮은 차원으로 변환하면서 모든 데이터 간의 관계가 성립되도록 처리하는 과정.
- 컴퓨터가 문자나 그림 등을 인식하게 하기위해 데이터를 벡터(숫자)로 변환하는 것.
- 단어 자체를 아스키코드나 유니코드로 처리해서 사용해왔지만, 추론을 할 수 없기 때문에, 숫자로 변환할 필요가 있음.
- Word Embedding 초기 모델에는 NNLM과 RNNLM이 있음.
- 최근에는 CBOW와 Skip-Gram 모델을 많이 사용하여 학습.
- Word Embedding 프로세스에는 신경망, 차원감소, 확률적 모델, 문맥상 표현 등의 여러 가지 처리과정들이 포함됨
NCE(Noise-Contrastive Estimation)
- CBOW와 Skip-Gram 모델에서 사용하는 비용 계산 알고리즘을 말함.
- 전체 데이터셋에 대해 SoftMax 함수를 적용하는 것이 아니라 샘플링으로 추출한 일부에 대해서만 적용하는 방법을 말함.
- k개의 대비되는 단어들을 noise distribution에서 구해서 (몬테카를로) 평균을 구하는 것이 기본 알고리즘. Hierarchical SoftMax와 Negative Sampling 등의 여러 가지 방법이 있음.
- 일반적으로 단어 개수가 많을 때 사용하고, NCE를 사용하면 문제를 (실제 분포에서 얻은 샘플)과 (인공적으로 만든 잡음 분포에서 얻은 샘플)을 구별하는 이진 분류 문제로 바꿀 수 있게 됨.
- Negative Sampling에서 사용하는 목적 함수는 결과값이 최대화될 수 있는 형태로 구성.
- 현재(목표, target, positive) 단어에는 높은 확률을 부여하고, 나머지 단어(negative, noise)에는 낮은 확률을 부여해서 가장 큰 값을 만들 수 있는 공식을 사용.
- 계산 비용에서 전체 단어 V를 계산하는 것이 아니라 선택한 k개의 noise 단어들만 계산하면 되기 때문에 효율적.
- 텐서플로우에서는 tf.nn.nce_loss()에 구현되어 있음.
Hierarchical SoftMax
- CBOW와 Skip-Gram 모델은 내부적으로 SoftMax 알고리즘을 사용해서 계산을 진행하는데, 모든 단어에 대해 계산을 하고 normalization을 진행해야 하는데, 이것은 시간이 너무 오래 걸릴 수 밖에 없음.
- 계산을 줄이는 방법으로 Hierarchical SoftMax와 Negative Sampling 알고리즘이 있음.
- Hierarchical SoftMax 알고리즘은 계산량이 많은 SoftMax 함수를 빠르게 계산가능한 multinomial distribution 함수로 대체.
- Multinomial distribution 함수는 루트에서 리프까지 가는 경로를 확률과 연동시켜서 계산 시간을 단축시킴.
- Word2vec 논문에서는 사용 빈도가 높은 단어에 대해 짧은 경로를 부여하는 Binary Huffman Tree를 사용.
- Huffman Tree는 경로의 길이가 일정한 full tree의 성질을 갖고 있기 때문에 성능 향상에는 더욱 이상적이게 됨.
Negative Sampling
- SoftMax 알고리즘을 몇 개의 샘플에 대해서만 적용하는 알고리즘.
- 전체 데이터로부터 일부만 뽑아서 SoftMax 계산을 수행하고 normalization을 진행하고, 이때 현재(목표) 단어는 반드시 계산을 수행해야 하기 때문에 Positive Sample이라 부르고, 나머지 단어를 Negative Sample이라고 부름.
- Negative Sampling에서는 나머지 단어에 해당하는 Negative Sample을 추출하는 방법이 핵심.
- 일반적으로 샘플링은 ‘Noise Distribution’(노이즈 분포)을 정의하고 그 분포를 이용하여 일정 개수를 추출하는데, 논문에서는 여러 분포를 실험적으로 사용해본 결과 ‘Unigram Distribution의 3/4승’을 이용한 분포가 unigram, uniform 등의 다른 분포들보다 훨씬 좋은 결과를 얻을 수 있었다고 함.
- ‘Unigram Distribution의 3/4승’ : 단어가 등장하는 비율에 비례하게 확률을 설정하는 분포하고 할 수 있음.
SoftMax 함수
- 입력 받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력값들의 총합은 항상 1이 되는 특성을 가진 함수
multinomial distribution function
- 다항 분포
- 여러 개의 값을 가질 수 있는 독립 확률변수들에 대한 확률분포로, 여러 번의 독립적 시행에서 각각의 값이 특정 횟수가 나타날 확률을 정의함.